DeepSeek: как китайский стартап с бюджетом в 6 миллионов долларов перевернул мировой рынок ИИ

Январь 2025 года. Воскресный вечер в Кремниевой долине.
Инженеры OpenAI открывают GitHub и видят там репозиторий. Китайская компания, о которой большинство из них слышат первый раз, выложила открытую языковую модель. Называется R1. И по первым тестам - она на уровне GPT-4o. При этом авторы пишут, что потратили на обучение меньше шести миллионов долларов. И два месяца.
На следующее утро акции Nvidia упали на 17%. Это было примерно 600 миллиардов долларов капитализации за один день.
Вот с этого момента весь мир узнал о DeepSeek.
Откуда вообще взялась эта компания
Чтобы понять DeepSeek, нужно сначала понять её основателя.
Лян Вэньфэн - основатель DeepSeek. Но прежде чем заняться нейросетями, он занимался деньгами. Конкретно - он основал хедж-фонд High-Flyer Quant в Ханчжоу, который управлял активами с помощью алгоритмической торговли. Фонд был хорош - достаточно хорош, чтобы к 2023 году его создатель мог позволить себе другой эксперимент.
Лян начал скупать GPU. Очень много GPU. Nvidia H800 - чипы, которые американские санкции ещё разрешали продавать в Китай. По некоторым оценкам, High-Flyer собрал один из крупнейших частных кластеров в стране. Это было сделано до того, как санкции ужесточились ещё больше.
В мае 2023 года появилась DeepSeek - как отдельная AI-лаборатория, дочерняя структура хедж-фонда. Команда небольшая. Цель - не монетизация, не IPO. По словам Ляна, цель была в том, чтобы просто понять, как устроены большие модели. И попробовать сделать их лучше.
Звучит наивно. Получилось иначе.
Первые модели - учёба на чужих ошибках
В 2023 году DeepSeek выпустила первые модели серии V1 и Coder. Они были хорошие, но не потрясающие. Команда честно копировала архитектурные решения из открытых публикаций - Meta LLaMA, исследования Google по трансформерам, работы из Стэнфорда. Читала всё, что публиковалось в открытом доступе, и методично применяла.
Параллельно шла своя исследовательская работа. Команда публиковала статьи - про механизмы внимания, про эффективное обучение, про архитектуру MoE (Mixture of Experts). Западные исследователи читали эти статьи и в целом оценивали их высоко. Качественная инженерия, чистые идеи.
Конец 2024 года принёс V3. Вот тут что-то щёлкнуло.
DeepSeek V3 вышел с производительностью на уровне лучших закрытых моделей - и при этом был открытым. Это само по себе было нонсенсом: до этого открытые модели заметно уступали GPT-4 и Claude. Но самое интересное было в другом - в том, как именно его обучили.
Момент, который всё изменил: история R1
Декабрь 2024. DeepSeek тихо выкладывает техническую статью о новом подходе к обучению с подкреплением. Это R1.
Суть в следующем. Обычно большие модели обучают в два этапа: сначала предобучение на огромных объёмах текста, потом тонкая настройка с человеческой обратной связью (RLHF). Это дорого и медленно. DeepSeek нашли способ обучить модель рассуждать - настоящему пошаговому рассуждению - с помощью чистого обучения с подкреплением, без дорогостоящей разметки данных людьми.
Команда заявила, что потратила меньше шести миллионов долларов и два месяца. При этом R1 бил или повторял GPT-4o на многих стандартных тестах.
В Кремниевой долине это приняли по-разному. Часть людей говорила, что цифры занижены - что настоящие затраты выше, что за ними стоят годы предыдущей инфраструктуры. Возможно, это правда. Но даже если умножить цифру в десять раз - получается 60 миллионов долларов против нескольких миллиардов, которые тратят OpenAI и Anthropic на сопоставимые модели.
Несколько американских штатов, Австралия, Тайвань, Южная Корея, Дания и Италия ввели ограничения или запреты на использование DeepSeek R1, сославшись на проблемы конфиденциальности и национальной безопасности.
Это было странное сочетание: модель заблокировали те, кто боялся её влияния - и одновременно начали копировать её методы обучения. Microsoft, Google, Meta в течение нескольких месяцев опубликовали работы, использующие похожие подходы к RL-обучению.
Как DeepSeek обходит проблему чипов
Здесь самое интересное - с технической точки зрения.
После того как американские санкции закрыли Китаю доступ к Nvidia H100 и A100, у DeepSeek была альтернатива: более слабые чипы. H800 - версия H100 с урезанной межчиповой шириной канала. Это примерно как строить небоскрёб, когда у тебя нет бетона высшей марки, - нужно придумывать другие конструктивные решения.
И они придумывали. Архитектура MoE (Mixture of Experts) стала их главным инструментом. Идея не новая - Google предложила её ещё в 2017 году. Но DeepSeek довела её до практической эффективности на ограниченном железе.
Смысл MoE в том, что модель не активирует все параметры для каждого запроса. DeepSeek V4-Pro содержит 1,6 триллиона параметров всего, но активных при работе - только 49 миллиардов. Это как библиотека с миллионом книг, где для ответа на конкретный вопрос берут только нужные 30 томов, а не тащат всё сразу.
Плюс собственные разработки в области механизмов внимания. DeepSeek V4 использует DSA2 - гибрид двух подходов к обработке контекста, который позволяет эффективно работать с длинными последовательностями без квадратичного роста вычислительной нагрузки.
Результат: модели, которые конкурируют с американскими флагманами, но требуют значительно меньше вычислительных ресурсов для инференса.
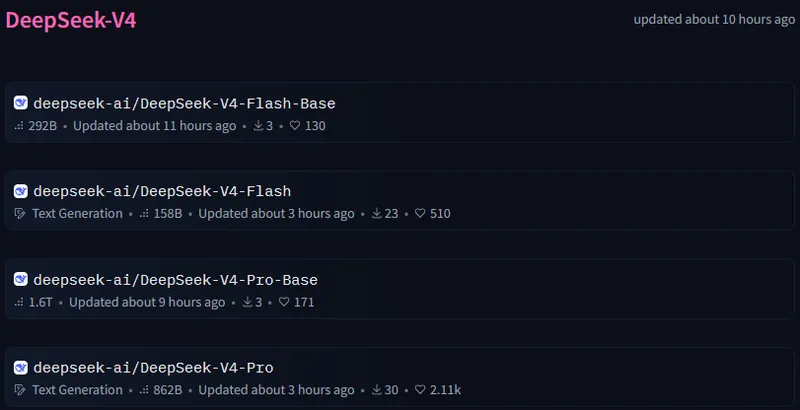
DeepSeek V4: что вышло 24 апреля 2026 года
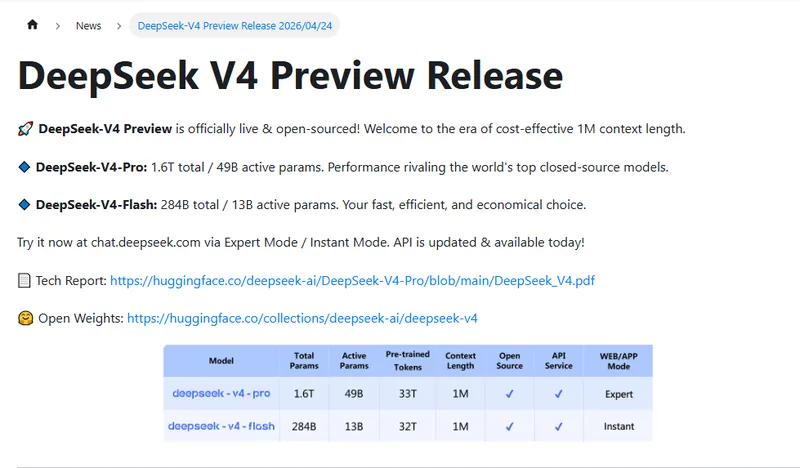
24 апреля 2026 года DeepSeek выпустила preview-версии двух моделей: V4-Pro и V4-Flash. Обе доступны через веб-интерфейс и API сразу после анонса.
Это не финальный релиз - это preview. Компания традиционно выпускает предварительные версии для сбора обратной связи, а финальную полируют ещё несколько недель.
V4-Pro - флагман
1,6 трлн параметров всего, 49 млрд активных. На Hugging Face весит 865 ГБ. Лицензия MIT - можно использовать и модифицировать свободно, включая коммерческое применение.
Это сейчас крупнейшая открытая модель с опубликованным кодом в мире. Больше, чем все конкуренты в открытом сегменте.
По бенчмаркам: DeepSeek заявляет, что V4-Pro превосходит все открытые модели в математике и программировании, и уступает только Gemini 3.1-Pro - закрытой модели Google - по базе знаний о мире.
На MMLU-Pro (тест на экспертные знания) DeepSeek V4 набирает 91,2 балла. Gemini 3.1 Pro Preview - 90,0. GPT-5.3 - 88,4. Claude Opus 4.6 - 86,7.
V4-Flash - быстрая версия
284 млрд параметров всего, 13 млрд активных. Весит 160 ГБ - теоретически может запуститься на мощном потребительском железе с достаточным количеством RAM.
Это модель для задач, где нужна скорость, а не максимальное качество. Код, быстрые ответы, высокочастотные API-запросы.
Контекст 1 миллион токенов
Обе модели поддерживают контекст в 1 миллион токенов. Для понимания масштаба - это примерно 750 тысяч слов. Полный текст "Войны и мира" - и ещё останется место.
Это заметно расширяет реальные сценарии: модели могут обрабатывать длинные документы и большие кодовые базы целиком, без разбиения на части.
Агентные способности
V4 получила заметные улучшения в агентных способностях - возможности автономно выполнять задачи: писать и запускать код, работать с файлами, последовательно решать многошаговые проблемы.
Архитектурно V4 работает в двух режимах. Быстрый режим - для повседневных запросов, текста, изображений, файлов. Экспертный режим - для сложного анализа и глубокого рассуждения, с расширенным поиском.
Чипы
Для поддержки V4 DeepSeek использует чипы Huawei Ascend 950 и Cambricon - без Nvidia. Huawei подтвердила поддержку через технологию Supernode, объединяющую большие кластеры Ascend-процессоров.
Это принципиальный момент. R1 обучали частично на Nvidia H800. V4 - уже на отечественных китайских чипах. Если это подтвердится, это означает, что американские экспортные ограничения на GPU перестали работать как барьер.
Цены - вот где DeepSeek бьёт всех
V4-Flash: $0,14 за 1 млн входных токенов и $0,28 за выходные. V4-Pro: $1,74 и $3,48 соответственно. Flash дешевле даже самой доступной модели OpenAI - GPT-5.4 Nano.
Для разработчика это не просто скидка. Это разница между "можем себе позволить запустить в продакшн" и "слишком дорого".
Возьмём пример. Продукт делает 10 миллионов запросов в месяц, средний запрос - 500 входных токенов и 200 выходных. Это 5 млрд входных токенов и 2 млрд выходных в месяц.
С V4-Flash: 5 × 0,14 + 2 × 0,28 = $700 + $560 = примерно $1 260 в месяц.
С GPT-5.3 при аналогичных параметрах - разговор идёт о десятках тысяч долларов.
Спорные моменты: что остаётся под вопросом
Картина была бы неполной без обратной стороны.
OpenAI и Anthropic обвиняют DeepSeek в незаконном извлечении возможностей из своих моделей - так называемом дистилляции. Белый дом также выпустил меморандум, обвиняющий иностранные структуры - прежде всего китайские - в "промышленных кампаниях" по дистилляции американских ИИ-систем.
Дистилляция - это процесс, при котором одна модель учится на выходах другой. Это технически законно, но американские компании считают, что она происходит в нарушение условий использования их сервисов.
DeepSeek обвинения не прокомментировала.
Второй вопрос - безопасность данных. Ряд стран, включая США, Австралию и Италию, ввели ограничения на использование DeepSeek в государственных структурах, ссылаясь на риски конфиденциальности. Сервер модели находится в Китае, данные пользователей попадают под китайское законодательство.
Для корпоративных пользователей это важно. Для тех, кто использует открытый код локально - нет: модель работает на вашем железе.
Третье - реальные затраты на обучение. Цифра в 6 миллионов долларов для R1 вызывает скептицизм у части исследователей. За ней не учитывается стоимость предыдущей инфраструктуры, экспериментов, которые не вошли в финальный релиз. Но даже с поправкой на это - экономия на вычислениях у DeepSeek реальная. Их архитектурные решения объективно эффективнее.
Что это означает для рынка
По данным Stanford AI Index 2026, Китай "фактически закрыл" разрыв в производительности ИИ с американскими конкурентами.
Полтора года назад это звучало бы как преувеличение. Сейчас - нет.
Конкретные последствия:
Цены на API по всему рынку падают. Когда появился V3, OpenAI снизила цены на несколько своих моделей. После R1 - ещё раз. DeepSeek создаёт ценовое давление, которое выгодно разработчикам.
Открытый исходный код меняет расстановку сил. Компании, которые не хотят зависеть от американских поставщиков, получают мощную альтернативу. Это особенно актуально для рынков, которые имеют напряжённые отношения с США.
Для России это практически означает: есть мощная открытая модель, которую можно развернуть локально, без зависимости от зарубежных API. GigaChat и YandexGPT получают серьёзного конкурента в нишах кода и математики.
Как попробовать DeepSeek V4 прямо сейчас
Через веб-интерфейс
Зайдите на chat.deepseek.com. Бесплатно, без сложной регистрации. Выберите модель V4 в интерфейсе. Работает из России - без дополнительных настроек.
Через API
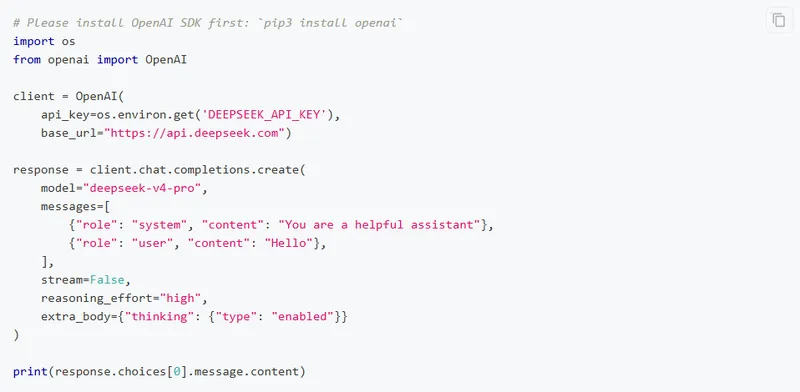
Зарегистрируйтесь на platform.deepseek.com, получите API-ключ. Синтаксис совместим с OpenAI SDK - если у вас уже есть код для работы с ChatGPT, смена модели займёт одну строку.
Локально
V4-Flash весит 160 ГБ на Hugging Face - теоретически может запуститься на мощном локальном железе. V4-Pro (865 ГБ) потребует серьёзного сервера. Квантизированные версии появятся в ближайшие дни - команда Unsloth традиционно выпускает их быстро после каждого релиза DeepSeek.