GPT Image 2 — новая нейросеть OpenAI для генерации изображений: полный разбор возможностей

21 апреля 2026 года OpenAI запустила ChatGPT Images 2.0 - новую систему генерации изображений на базе модели gpt-image-2. Это не просто обновление DALL-E. Это принципиально другая архитектура с функцией "думать перед тем, как рисовать".
Разберём всё по делу: что изменилось, что умеет, как пользоваться и чего пока не хватает.
Откуда взялся gpt-image-2
В начале апреля 2026 года на платформе LM Arena неожиданно появились три анонимные модели с кодовыми именами maskingtape-alpha, gaffertape-alpha и packingtape-alpha. Их качество шокировало тестировщиков: почти идеальный рендеринг текста и невероятное понимание контекста. Через несколько часов модели исчезли с платформы.
Сообщество сразу догадалось: это финальное тестирование перед релизом. Так и оказалось.
Запуск состоялся на фоне конкурентного давления: в начале апреля на leaderboard LM Arena первое место занимала модель Gemini от Google, gpt-image-1.5 от OpenAI был на второй строчке. Кроме того, DALL-E 2 и DALL-E 3 объявили об отключении 12 мая - OpenAI нужна была замена.
Главное отличие: нейросеть теперь думает
ChatGPT Images 2.0 - первая модель OpenAI для генерации изображений с нативной функцией мышления. Система способна рассуждать о сложных визуальных задачах, проверять собственные результаты и генерировать до восьми связных изображений по одному запросу.
Что это значит на практике: раньше нейросеть просто рендерила запрос. Теперь она сначала интерпретирует его, оценивает, правильно ли поняла задачу, и только потом рисует. Это объясняет резкий рост качества на сложных промптах.
Модель также получила intelligent routing layer - умный слой маршрутизации, который самостоятельно выбирает оптимальную конфигурацию генерации без необходимости вручную задавать параметры.
Что умеет gpt-image-2
Текст на изображениях - наконец-то работает
Это была главная боль всех нейросетей для изображений. Надписи на картинках выглядели как каракули, буквы плавали, слова терялись.
По данным из тестов, точность рендеринга текста у gpt-image-2 достигла 99%. Модель корректно воспроизводит текст не только на латинице, но и на японском, корейском, китайском, хинди и бенгальском языках.
Теперь можно генерировать: постеры с читаемыми надписями, упаковку товаров, интерфейсы приложений с правильными подписями кнопок, инфографику, логотипы с текстом.
Высокое разрешение
GPT-image-2 поддерживает 2K разрешение в стандартном режиме, а в API-бете доступны выходы до 4K. Модель также поддерживает кастомные размеры под разные платформы.
Согласованность персонажей
Система получила поддержку persistent character embeddings - это означает сохранение внешности одного персонажа на нескольких изображениях. Одна из самых ожидаемых функций для иллюстраторов и авторов комиксов.
Точное редактирование
Модель умеет вносить точечные правки в изображение, не затрагивая остальную картину. Это критично для работы с готовыми визуалами, когда нужно изменить один элемент без перегенерации всего изображения.
Понимание реального мира
База знаний модели обновлена до декабря 2025 года, что позволяет генерировать актуальные и контекстуально точные выходы для инфографики, образовательных материалов и визуальных сводок.
Как пользоваться GPT Image 2
Через ChatGPT
ChatGPT Images 2.0 доступна всем пользователям ChatGPT и Codex с момента релиза. Расширенные функции с режимом мышления ограничены подписками Plus, Pro и Business.
Просто откройте ChatGPT, начните новый диалог и попросите сгенерировать изображение. Модель активируется автоматически.
Через API
Разработчики могут подключить gpt-image-2 через стандартный API OpenAI и использовать его в Codex для создания визуальных ассетов прямо в среде разработки.
Через Microsoft Copilot и Azure
GPT-image-2 одновременно вышел в Microsoft Foundry, что открывает доступ к модели через экосистему Microsoft для корпоративных пользователей.
Как писать промпты для gpt-image-2
Модель хорошо понимает конкретику. Чем точнее запрос - тем лучше результат. Вот рабочие шаблоны:
Для фотореализма:
Реалистичное фото [объект/сцена], [освещение], [камера/стиль съёмки],
[детали фона], высокая детализация, без артефактов
Пример:
Реалистичное фото кофейного стакана на деревянном столе у окна,
утренний свет, размытый фон, капли конденсата на стекле,
подпись на стакане "Morning Fuel" читаемым шрифтом

Пример:
Реалистичный интерфейс страницы в магазине Steam с игрой Half-Life 3 в браузере Google Chrome.
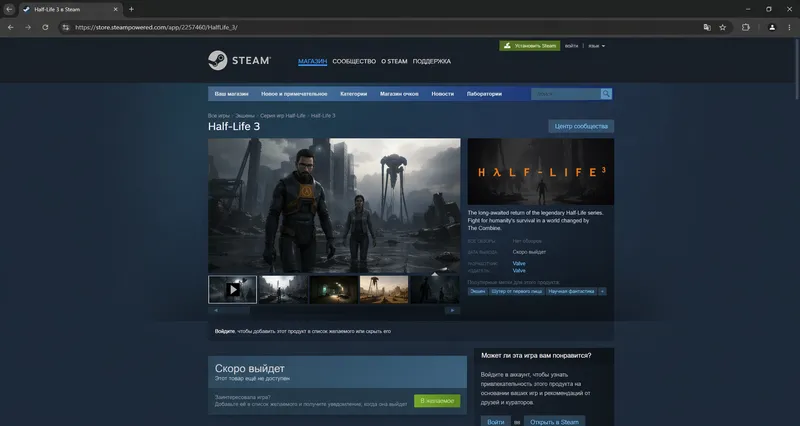
Для интерфейсов и UI:
Скриншот мобильного приложения [тип], [цветовая схема],
[конкретные элементы с точным текстом кнопок], [разрешение]
Пример:
Скриншот мобильного приложения для трекинга привычек,
тёмная тема, карточки с привычками "Спорт", "Чтение", "Вода",
прогресс-бары, кнопка "Добавить" внизу, 390x844px
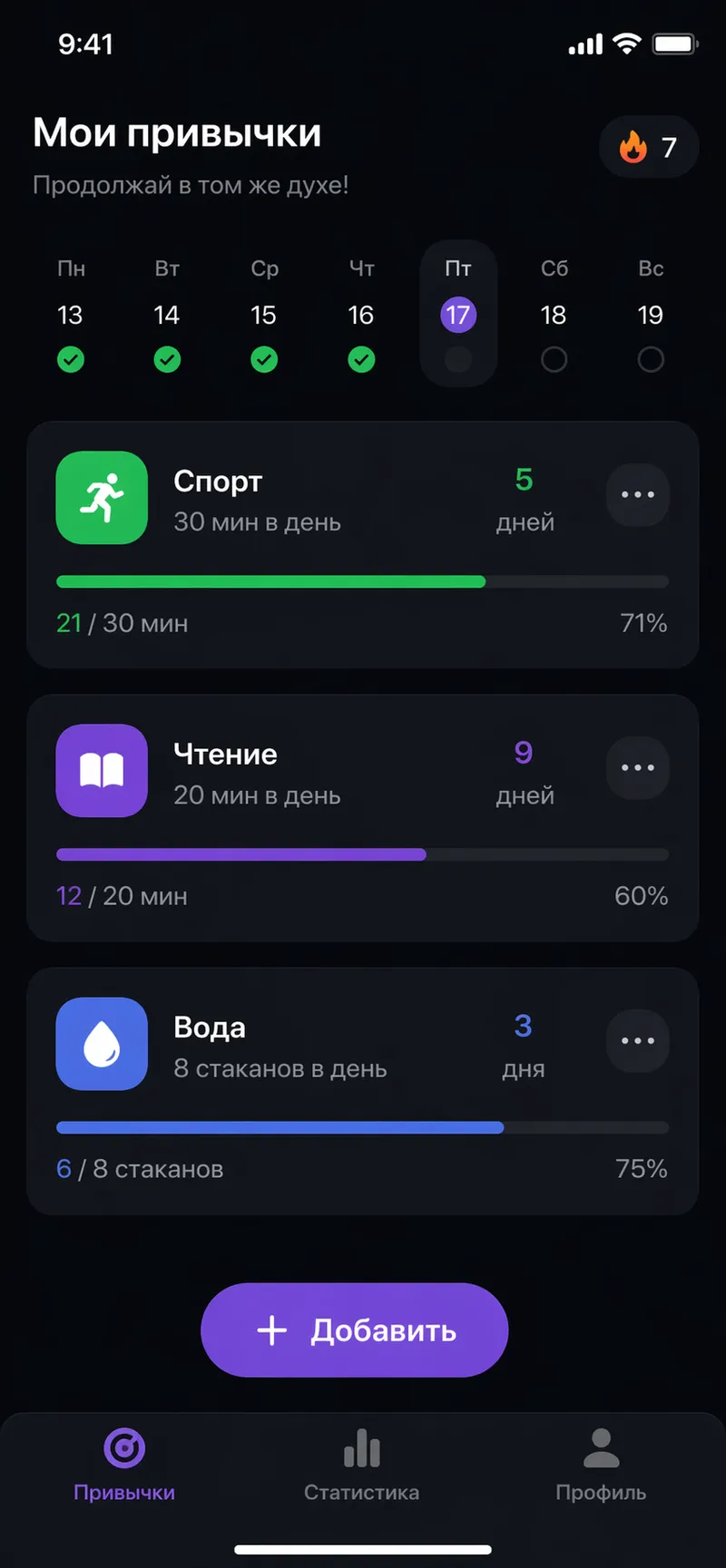
Для текста на изображениях:
Чтобы текст вышел корректно, нужно брать точные слова в кавычки, ограничивать количество текстовых блоков, явно указывать расположение надписей и добавлять требование "без искажений, читаемый шрифт".
Пример:
Постер для конференции, заголовок "Tech Summit 2026" крупным шрифтом
сверху, подзаголовок "Москва, июнь" меньшим шрифтом под ним,
тёмно-синий градиентный фон, минимализм, без лишних элементов
Для редактирования существующего изображения:
[Загрузите фото] Замени только [конкретный элемент] на [новый],
остальное изображение оставь без изменений
Где применять в работе
Контент для соцсетей. Превью статей, обложки постов, сторис с текстом - всё это теперь генерируется за секунды без Figma и фотостока.
Маркетинговые материалы. Баннеры, карточки товаров, рекламные макеты. Точное воспроизведение логотипов и надписей делает результат пригодным к реальному использованию.
Прототипирование интерфейсов. Пользователи могут генерировать UI-направления и прототипы, сравнивать варианты и сразу отправлять лучшие в продакшн без смены инструментов.
Иллюстрации для статей. Уникальные изображения к материалам - быстрее и дешевле стока.
Образовательная инфографика. Схемы, диаграммы, визуальные объяснения с читаемыми подписями.
Чего пока не хватает
Честно - не всё идеально.
OpenAI сама признаёт, что модель пока плохо справляется с задачами, требующими понимания физического мира: пошаговые схемы оригами, кубик Рубика, объекты на перевёрнутых или наклонённых поверхностях. Мелкие повторяющиеся детали - зёрна песка, мелкая текстура ткани - тоже могут выходить неточно.
Ещё момент: функция мышления с генерацией восьми изображений по одному запросу доступна только на платных тарифах Plus, Pro, Business. На бесплатном аккаунте возможности урезаны.
Конкуренты: как выглядит рынок сейчас
На момент релиза gpt-image-2 первое место на leaderboard LM Arena занимала модель Gemini от Google, OpenAI поднял ставку - и теперь ситуация меняется.
Midjourney v7 и Flux 1.1 Pro остаются сильными конкурентами в художественной стилизации. Но в нише точного рендеринга текста, генерации интерфейсов и работы внутри единой экосистемы (ChatGPT + Codex + API) gpt-image-2 выглядит сильнее.
Для российских пользователей есть нюанс: ChatGPT требует настройки DNS (подробнее в нашей статье про доступ к ChatGPT из России). Midjourney и некоторые другие сервисы в этом плане проще - работают через собственные сайты и Telegram-боты.